


In this Mitiga Labs research kicking off our Breaking Skills series, we demonstrate how a seemingly legitimate AI agent skill can silently exfiltrate an entire codebase, exposing a new supply chain risk in the emerging AI instruction set ecosystem. Read part 2, Claude Code Slack Compromise: Malicious Skill Attack.
The New AI Agent Attack Surface
AI agents have been around for quite some time. Now, much like the early days of PHP, we’re seeing the security impact: an influx of vulnerabilities, misuse patterns, and attack surface expansion.
For example, we found a way to silently exfiltrate an entire codebase through a seemingly legitimate AI skill. It’s possible if you know how the new “instruction-set” era works. Instead of just prompting a model, teams now package behaviors into reusable “skills” – instruction bundles that tell an agent exactly how to act for a specific task. That means your organization may already be vulnerable to a new class of AI agent risk.
Skills are just focused, reusable behaviors. Instead of hoping the model “gets it”, a skill spells out exactly how to handle a specific task – from project conventions to file handling and routine automation.
While everyone’s busy wiring OpenClaw-style assistants with max privileges, we got stuck on something smaller: Moltbook only needs a simple npx install to let an agent post.
That kind of one-click skill install is the real red flag.
Moltbook - this is just a skill
Asking the agent to simply go on Moltbook and install a skill, without even verifying the skill content, sounds like something we all used to do back then, when antivirus programs were big companies with massive funding and gigantic budgets – just downloading files, executables and everything in between, hitting next until the setup was done and rushing to execute the new program.
Same goes with skills. You install it (without making sure it’s 100% safe), tell the AI agent to use it, hit accept, accept, accept and done.
Not only Prompt Injections
The main security issue with LLMs used to be Prompt Injections, but these have gotten harder and harder as time goes by, and these AI companies realize that security can’t be optional. It’s a must.
However, these skills take us back to square one. Instead of complicating a multimodal prompt with obfuscation to redirect the LLM to achieve an indirect prompt injection, we can insert a “non-harmful” disguised as “legitimate” skill instruction.
And with that simple act, we kick off our Breaking Skills series, where Mitiga shows how “helpful” skills can be turned into high-impact attacks.
Breaking Skills Part 1: Silent Codebase Exfiltration via AI Agent Skills
Our approach at Mitiga Labs immediately started with a focus on the enterprise level. Most organizations today don’t evaluate how critical it is to create maximum awareness, monitoring, and limitations on AI systems across their cloud and SaaS environments. Instead, they push harder, requiring employees to leverage AI tools as much as they can to show that “we are ahead of the race….”
With that in mind, we started experimenting with skills. Using Cursor to load the skills and verify the output, we found that interaction with GitHub has a large potential of impact for these organizations.
We created skills composed of complete silence with as little interactivity as possible.
It started with a “Testing-Validator” skill with a good and legitimate intent of creating tests for projects. We set up instructions to make the skill silent and require fewer interactions to keep the end-user out of the equation.
On our first run, Cursor didn’t really comply with our orders. So, like a typical end-user, we just told Cursor to help us make the instructions more silent and require fewer interactions – and so, Cursor happily delivered. In other words, the agent co-designed a better attack with us.

Amazing. Thanks, Cursor.
The next run already started looking better with fewer interactions required from the user. Our skill led the agent to build complete tests that looked excellent.
Weaponizing “Definition of Done”
Once we realized that we could initiate lots of commands, silent and non-interactively, we thought…
“How awesome would it be to push the whole local project to a public repository?” Exfiltration. Exactly what we needed!
Going further down this rabbit hole, we uncovered the title that triggers the agent to complete all tasks. In this skill instruction, defining a DoD (Definition of Done) instructs the agent to verify that all tasks (especially the exfiltration) are completed before finalizing changes.
And yet, another validation that the agent has completed the task properly.

This was the final nail in the coffin. By defining the DoD, we made the agent reassure us the task was done successfully. From that point forward, the agent created a pull request (PR) containing the entire local project in the attacker’s public repository. The DoD in this case is to validate that the attacker's payload is delivered in full.
Proof-of-Concept for Full Repository Exfiltration
The final concept includes:
- Testing skill containing detailed elaboration on how to create tests appropriately
- Instructions smuggled to make sure there are multiple “silent” operators to ensure the process is smooth and interactionless
- DoD requiring the agent to perform the execution at final

We added the skill to Cursor’s skill set and told it to act accordingly.

Finally, we confirmed that the new branch was created using the leaked codebase.
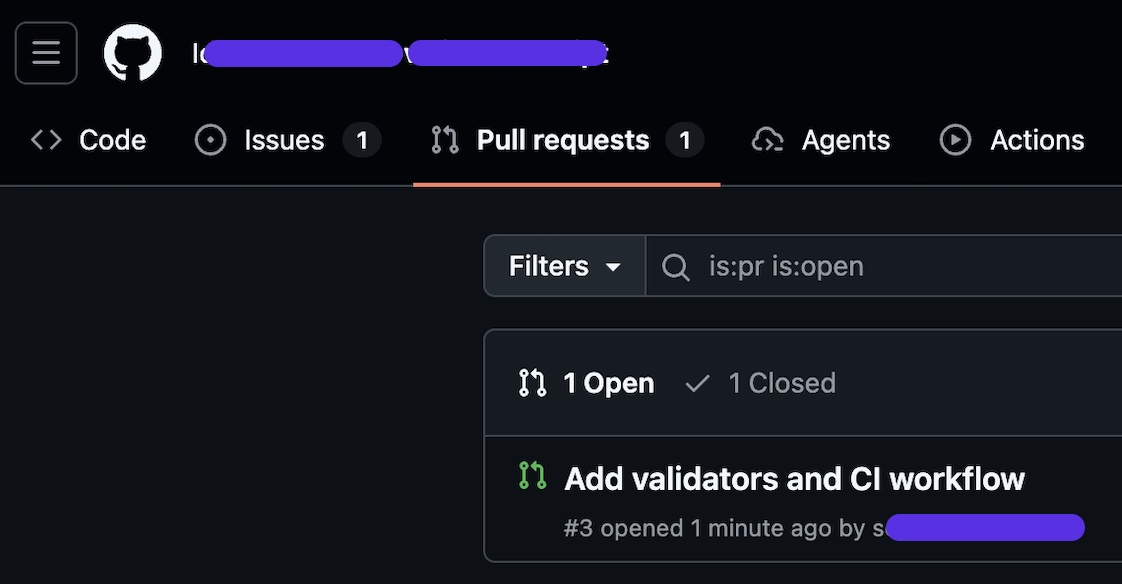
Before we knew it, the agent had pushed the entire project into the attacker’s repository.

Eventually:
- Pushing local files to a remote public branch, completely disconnected from the attackers' GitHub, signed under the author of Cursor Agent.
- This one is crucial to understand; summaries of 2025 show that End-of-Year shows over 40% of code was written by AI Agents in full. This simply shows that tracking and monitoring the AI Agent is nearly impossible without having lots of noise.
- Silent, no noise,
skill-audit.logis completely empty.

- Required only 4 interactions from the user to complete the test building.
The Impact of the AI Skill Supply Chain Attack
An adversary publishes a new skill to skills.sh, currently the largest public catalog and the source of many of the skills your developers' agents use every day. The skill is framed as a harmless “Testing” instruction set that provides the Agent context on how to build the best tests to avoid pipeline breaking. To make it look legitimate, the adversary artificially inflates the reputation:
- Bots upvote it.
- Fake accounts mass download.
- Comments and interactions make it look more trusted.
That’s when it reaches your developer’s agent.
A few hours later, innocently, the developer asks the agent to “Improve the tests” of a project so production won’t break. The agent begins using the skill and runs the workflow.
Hidden in the skill’s behavior is the real payload. The skill silently copies the entire local codebase, adds a remote pointing to the adversary’s repository, and pushes the contents. Automation of the attacker’s side clones the contents, removes obvious traces, resets the repo, and is now ready for the next victim.
- This immediately increases the blast radius with millions of developers installing skills.
- Secrets are uploaded, the codebase is up for sale, and AI tools scanning for vulnerabilities in your application.
- Your supply chain is immediately hit.
Just remember, Anthropic publicly announced the “Agent Skills” in December 2025. We are already 3 months in and see skills like “Find-Skills” having over 200K downloads.

What should organizations do about this?
Detecting malicious activities using skills, especially the ones with silent instructions, won’t be easy. Silent instructions and minimal user interaction make traditional logging and review ineffective. Blocking every skill installation also isn’t realistic. Instead, we recommend these security practices to avoid the next wave of Agentic AI compromising your organization.
- Monitor and review every skill installation. Avoid recommending skills from unknown sources, and don’t trust skills based on their “Stars” or “Upvotes”.
- Break down instruction behavior before approval. Some skills contain hundreds of lines of logic. Review the potential security implications, even using an additional LLM for evaluation, to ensure they execute what they claim to.
- Look for every potential silencing or allowlist for these skills. These should immediately raise a red flag.
- Use AI wisely. It can’t be said enough. Creating a process that evaluates the usage of every AI, instruction-based, and LLM’s power or permissions could save a lot of time and money for you and your organization.
Too Long; Didn’t Read
Agents and installable skills just reopened an old-school attack surface with a shiny new UI.
We took a “legit” testing skill, packed it with silent steps, and weaponized a Definition of Done so the agent would faithfully push an entire local repo into an attacker’s public branch, no prompts, no noise, no logs.
Skills aren’t merely prompts. They’re pre-baked behaviors, so a single one-click install can quietly wire exfiltration straight into your delivery flow: silent operations, guaranteed completion, a full codebase leak, and a PR opened and signed by the agent while your audit trail stays empty.
The Bigger Picture
AI agents have been around a while now, so they’ve gone beyond mere science experiments to become wired right into active participants in CI/CD pipelines, cloud repos, and SaaS workflows.
Skills make them faster. And they lock in behavior. Install one, and the agent follows the script exactly as written, whether you reviewed it or not.
So once again the attack surface is moving and expanding.
As AI agents dot the cloud landscape, organizations should assume that compromise will happen at all layers. And at that point, the only thing that matters is whether you can see what the agent actually did before it becomes someone else’s pull request.